Dal 2017, l’intero settore dell’Intelligenza Artificiale ha marciato al ritmo di un solo tamburo: il Transformer. Architetture come GPT-4, Claude e Gemini sono meraviglie dell’ingegneria, ma condividono tutte un tallone d’Achille fondamentale: soffrono di “Amnesia Anterograda”.
Una volta terminato il pre-addestramento, il loro cervello è congelato. Non possono imparare dai loro errori in tempo reale senza un costoso ri-addestramento. Fino ad oggi.
I ricercatori di Google Research (guidati da Ali Behrouz e Vahab Mirrokni) hanno appena presentato a NeurIPS 2025 un paradigma che potrebbe mandare in pensione l’idea di “rete neurale statica”. Si chiama Nested Learning (NL) e il suo campione è un modello chiamato HOPE.
Il Paradigma: l’Illusione delle Architetture Profonde
Il titolo del paper è provocatorio: “Nested Learning: The Illusion of Deep Learning Architectures”.
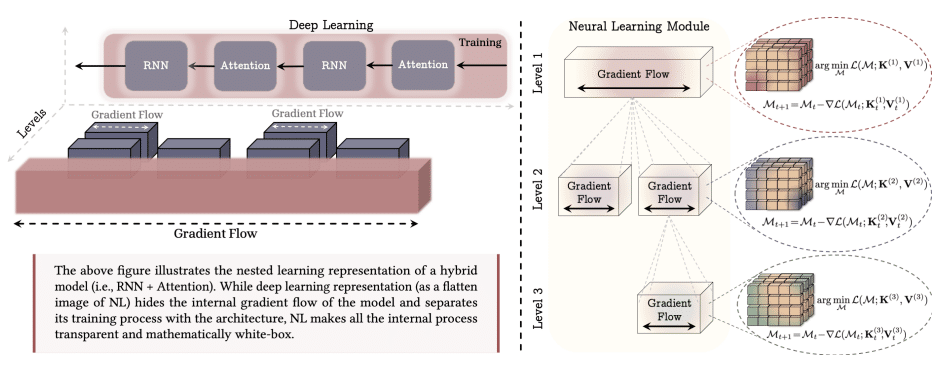
L’intuizione centrale è che abbiamo sempre guardato le reti neurali nel modo sbagliato. Invece di vederle come una “pila di strati” (layer) che processano dati sequenzialmente, dovremmo vederle come cicli di ottimizzazione annidati.
Il problema del “Cervello Congelato”
Attualmente, trattiamo l’architettura (il modello) e l’ottimizzatore (l’algoritmo che lo allena, es. Adam) come due entità separate.
-
Training: L’ottimizzatore cambia i pesi.
-
Inference (Uso): L’ottimizzatore si spegne. Il modello è statico.
Il Nested Learning fonde queste due fasi. Suggerisce che ogni componente del modello dovrebbe avere il proprio “ottimizzatore interno” che continua a girare anche durante l’uso.
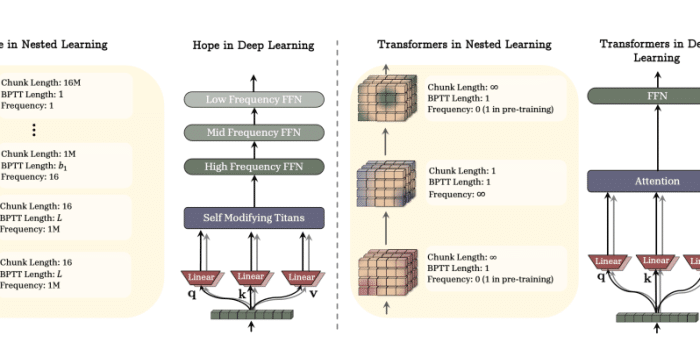
Deep Dive tecnico
Per capire perché questo è rivoluzionario, dobbiamo definire il glossario tecnico introdotto dal paper.
NL (Nested Learning)
È la teoria generale. Immagina il cervello umano: hai la memoria di lavoro (cosa hai appena letto) e la memoria a lungo termine (chi sei, le tue abilità). Il cervello non sovrascrive la tua personalità ogni volta che leggi un nuovo articolo.
Il NL implementa questo usando molteplici scale temporali:
-
Inner Loop (Veloce): Si adatta istantaneamente ai nuovi input (token).
-
Outer Loop (Lento): Consolida le informazioni solo quando necessario, evitando di cancellare le vecchie conoscenze.
CMS (Continuum Memory System)
Questa è la vera innovazione ingegneristica. Invece di una “Context Window” rigida (es. 128k token) che taglia via il passato, il CMS è un sistema di memoria fluido.
I ricercatori hanno scoperto che gli ottimizzatori classici (come SGD o Adam) possono essere riscritti matematicamente come moduli di memoria associativa. HOPE usa questa proprietà per “ricordare” i gradienti passati non come numeri da scartare, ma come memoria compressa.
CF (Catastrophic Forgetting)
Il nemico numero uno. Nei modelli attuali, se insegni a un’AI la “Fisica Quantistica” dopo averle insegnato la “Poesia”, i pesi della poesia vengono sovrascritti. HOPE risolve il CF isolando le nuove informazioni nei loop veloci e trasferendole nei loop lenti solo quando sono stabili, esattamente come il consolidamento della memoria durante il sonno negli esseri umani.
HOPE: Il modello Proof-of-Concept
Google non si è limitata alla teoria. Ha costruito HOPE (High-order Optimization Parameter Evolution – nome dedotto dal contesto del paper).
Nonostante abbia solo 1.3 Miliardi di parametri (un giocattolo rispetto ai 1.700 miliardi di GPT-4), HOPE mostra capacità emergenti che sfidano la sua taglia.
Confronto architetturale
| Caratteristica | Transformer (GPT/Gemini) | RNN Moderne (Mamba/RWKV) | HOPE (Nested Learning) |
| Meccanismo | Attention (Pesante) | State Space (Leggero) | Nested Optimization Loops |
| Memoria | Statica (Finestra fissa) | Compressa (Perdita di dettagli) | Dinamica (CMS) |
| Adattabilità | Nulla (Solo In-Context) | Nulla | Alta (Self-Modifying) |
| Gestione Contesto | “Dimentica” fuori dalla finestra | “Sfuma” nel tempo | Gerarchica (Veloce/Lento) |
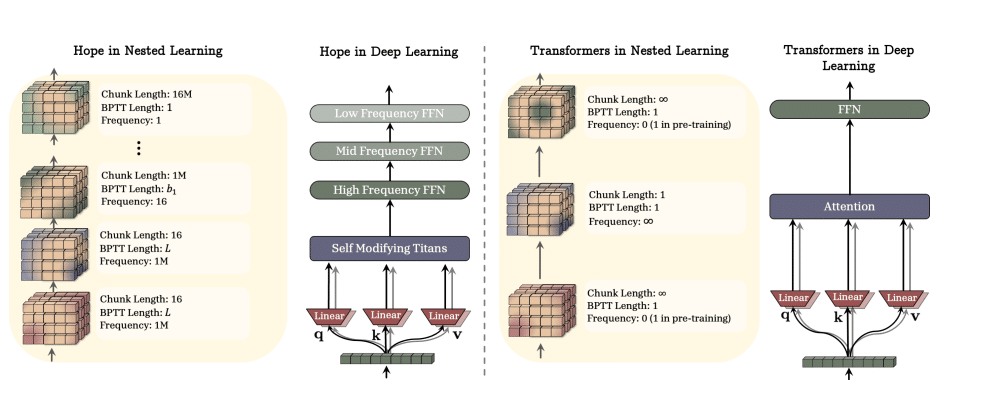
Un confronto dell’architettura di base di HOPE con i Transformer (la normalizzazione e i possibili componenti dipendenti dai dati sono stati rimossi per chiarezza). HOPE supera i modelli basati su Transformer e Mamba di pari dimensioni sia nel Language Modeling che nel Reasoning (Fonte: Google Research).
Implicazioni: perché cambia tutto?
A. Verso l’AGI (Artificial General Intelligence)
Un’intelligenza generale non può essere statica. Deve evolvere. HOPE è il primo passo verso sistemi Self-Modifying. Un’AI che usa HOPE potrebbe, teoricamente, leggere un manuale di medicina e “riscrivere” i propri pesi per diventare un dottore migliore, senza che gli ingegneri di Google debbano intervenire.
B. Efficienza su Edge Device
Poiché HOPE non deve tenere in memoria l’intera “Attention Matrix” di tutto ciò che ha letto, è estremamente leggero. Questo apre la porta a LLM ultra-intelligenti che girano localmente sul tuo smartphone, ricordando tutto ciò che hai fatto negli ultimi mesi senza mandare dati al cloud.
C. Il Test “Needle in a Haystack”
Nei test di recupero informazioni su testi lunghissimi, HOPE ha mostrato di poter recuperare dettagli minuscoli (l’ago) in contesti enormi (il pagliaio) meglio dei Transformer, perché il suo “loop lento” protegge l’informazione cruciale dall’essere cancellata dal rumore dei nuovi dati.
La mia opinione?
L’introduzione di HOPE sposta l’asse della ricerca dall’Ingegneria dei Dati (dare più testo a un modello stupido) all’Ingegneria Cognitiva (creare un modello che impara meglio).
-
Agenti Autonomi Veri: Un assistente basato su HOPE può “vivere” sul tuo laptop, imparare le tue abitudini giorno per giorno modificando i propri pesi, senza mai dover inviare i tuoi dati a un server centrale per il ri-addestramento.
-
Sostenibilità: Eliminando la necessità di ricalcolare l’attenzione su tutto lo storico ad ogni domanda, il costo energetico per inferenza crolla drasticamente.
-
Verso l’AGI: La capacità di un sistema di riscrivere le proprie regole di apprendimento (Meta-Learning) è considerata uno dei prerequisiti fondamentali per l’Intelligenza Generale Artificiale. HOPE è il primo passo concreto in questa direzione.
Il Nested Learning non è solo un miglioramento incrementale; è una correzione di rotta. Per un decennio abbiamo cercato di forzare i modelli a “fingere” di avere memoria dandogli finestre di contesto sempre più grandi. Google ha appena dimostrato che la soluzione non è una finestra più grande, ma un cervello strutturato diversamente.
Se i risultati di HOPE scaleranno su modelli da 100B+ parametri, l’era dei modelli statici è finita… forse 🙂
Fonti Ufficiali
Per chi vuole leggere i documenti originali:
-
📄 Il Paper (NeurIPS 2025): Nested Learning: The Illusion of Deep Learning Architectures (OpenReview)
-
🌐 Blog Google Research: Introducing Nested Learning
