
L’ecosistema dell’Information Retrieval e dell’ottimizzazione per i motori di ricerca sta attraversando una metamorfosi strutturale e paradigmatica di proporzioni storiche, segnando il definitivo tramonto dell’era basata sulla semplice indicizzazione e restituzione di collegamenti ipertestuali. La transizione da un modello di utilità basato sui tradizionali “dieci link blu” a un ecosistema di sintesi generativa e agentica ha raggiunto un punto di svolta critico. Questo cambiamento epocale è culminato nella concessione, all’inizio dell’anno 2026, di una tecnologia proprietaria che promette di ridefinire radicalmente il concetto stesso di navigazione web, disintermediando in modo aggressivo il rapporto tra creatori di contenuti, marchi commerciali e consumatori finali.
La presente analisi tecnica disseziona le fondamenta ingegneristiche, algoritmiche e strategiche di questa evoluzione, concentrandosi sulle specifiche dell’architettura generativa, sui meccanismi di valutazione automatizzata della qualità e sulle profonde conseguenze per il digital marketing, la gestione della presenza online e l’economia dell’editoria digitale. Il documento esplora l’integrazione di queste nuove tecnologie con i costrutti storici della profilazione utente, delineando un quadro in cui l’ottimizzazione per i motori di ricerca cessa di essere una disciplina di formattazione semantica per divenire una complessa ingegneria dell’esperienza totale.
L’Architettura e la Meccanica del Brevetto US12536233B1
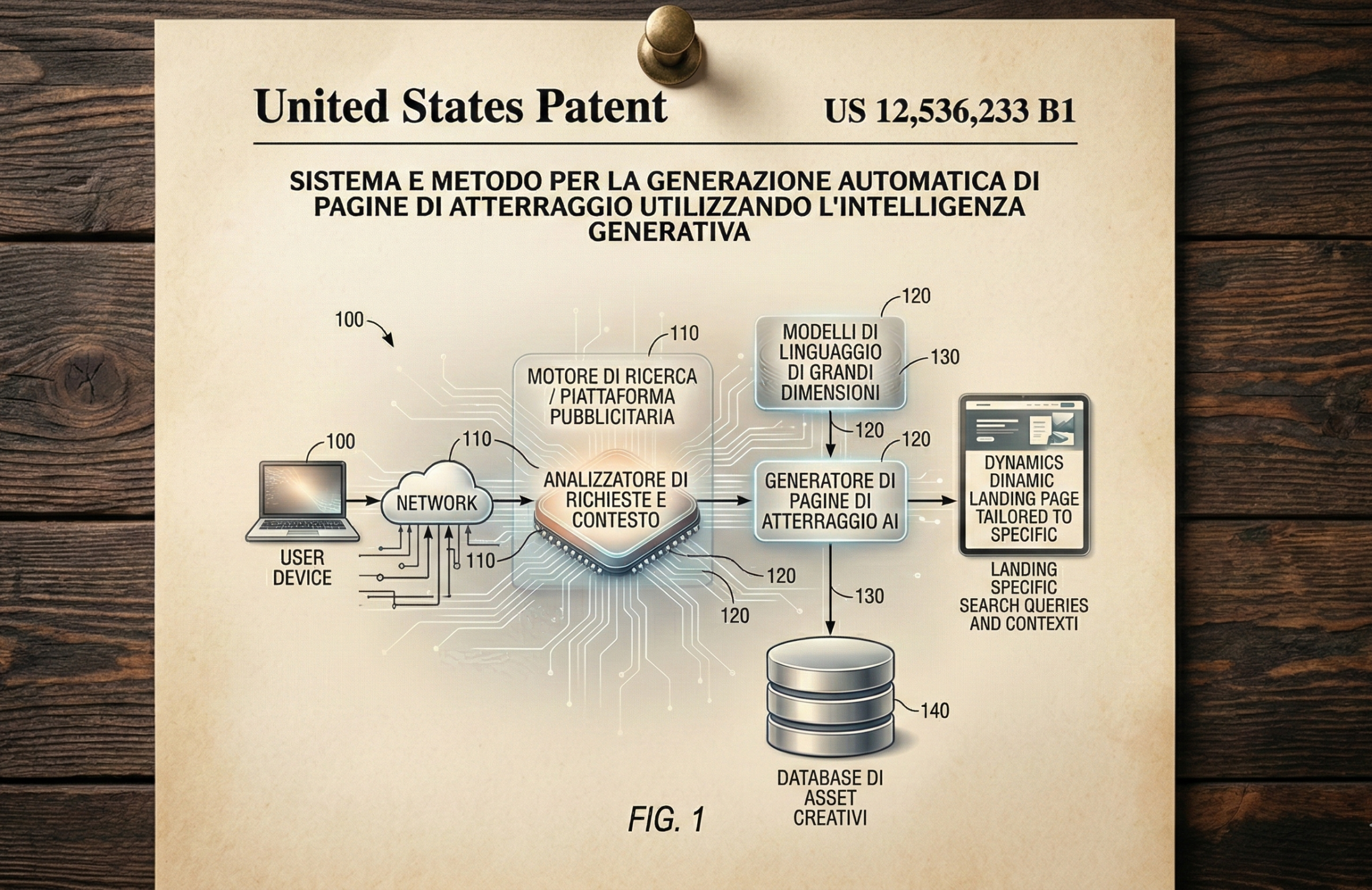
Il fulcro normativo, tecnologico e direzionale di questa rivoluzione algoritmica è rappresentato dal brevetto US12536233B1, depositato da Google LLC il 3 gennaio 2025, con una data di priorità originaria risalente al 25 luglio 2024, e ufficialmente pubblicato e concesso dall’ufficio brevetti il 27 gennaio 2026. Intitolato “AI-generated content page tailored to a specific user”, il documento brevettuale delinea un sistema automatizzato estremamente sofisticato, in grado di intercettare una query di ricerca e, qualora si verifichino specifiche condizioni di inefficienza strutturale o prestazionale, sostituire la pagina di destinazione (landing page) originale di un’organizzazione con una pagina web sintetica. Questa interfaccia alternativa non è preesistente, ma viene creata su misura, renderizzata in tempo reale da un modello di apprendimento automatico avanzato e ospitata direttamente sull’infrastruttura del motore di ricerca.
Il sistema operativo descritto dal brevetto si articola attraverso una sequenza di operazioni logiche, euristiche e computazionali che fondono il tradizionale Information Retrieval con le più moderne tecniche di generazione multimodale. Il processo computazionale ha inizio nel momento esatto in cui il motore di ricerca riceve una query da un dispositivo hardware associato a un account utente specifico e autenticato. In una prima fase, il sistema genera un’astrazione di una pagina dei risultati di ricerca (SERP) standard, la quale include un risultato primario organicamente associato alla landing page originale dell’organizzazione, del marchio o dell’editore interrogato.
Tuttavia, prima che questa SERP venga instradata e presentata all’utente nella sua forma definitiva, un modulo di valutazione algoritmica invisibile interviene per calcolare un valore metrico denominato “Landing Page Score” (Punteggio della Pagina di Atterraggio). Qualora questo punteggio composito superi una soglia prestabilita di inefficienza, inadeguatezza qualitativa o attrito transazionale, il sistema interviene alterando dinamicamente il payload della SERP. Il link di navigazione originale viene soppresso o declassato, e sostituito con un collegamento ipertestuale diretto verso un’interfaccia generata dall’intelligenza artificiale, costruita specificamente per quell’utente, per quella particolare query e per quel preciso istante temporale.
La tabella seguente riassume i metadati fondamentali e le classificazioni ingegneristiche associati a questa proprietà intellettuale, delineando il perimetro legale, temporale e tecnologico entro cui questa innovazione è stata sviluppata e protetta.
| Metadato Brevettuale e Classificazione | Dettaglio Specifico e Implicazione Tecnica |
| Numero di Pubblicazione USPTO | US12536233B1 |
| Titolo Ufficiale del Brevetto | AI-generated content page tailored to a specific user |
| Assegnatario Legale | Google LLC |
| Inventori Registrati | Caren Zeng, Rushil Grover, Timothy Benjamin Whalin, Lauren Marjorie Bedford, Pallavi Satyan, Ethan Milo Mann |
| Data di Deposito (Filing Date) | 3 Gennaio 2025 |
| Data di Priorità (Priority Date) | 25 Luglio 2024 |
| Data di Concessione (Grant Date) | 27 Gennaio 2026 |
| Scadenza Naturale Prevista | 3 Gennaio 2045 |
| Classificazione G06F16/00 & G06F16/9535 | Information Retrieval avanzato e personalizzazione della ricerca basata su profili utente dinamici. |
| Classificazione G06N20/00 & G06N3/0475 | Machine Learning, Reti Neurali Generative e architetture di deep learning per la sintesi di contenuti. |
| Classificazione H04L51/02 | Sistemi di messaggistica generati da chatbot e interfacce conversazionali integrate. |
La complessità e l’ambizione di questa architettura risiedono nella sua natura profondamente ibrida, che combina tecniche di Information Retrieval basate su grafi e indici invertiti con reti neurali generative di ultima generazione. Il documento brevettuale descrive minuziosamente un framework di addestramento specifico, denominato “Method 1000”, preposto al perfezionamento dei modelli di apprendimento automatico incaricati della generazione simultanea di testo, elementi di design, immagini, audio e strutture dati.
Questo metodo si basa sull’acquisizione massiva di dataset di istanze di addestramento, sia etichettate da revisori umani (quality raters) sia non etichettate, che vengono processate attraverso i pesi sinaptici del modello per generare un output predittivo del layout web ideale. L’ottimizzazione e la retropropagazione dell’errore (backpropagation) all’interno della rete neurale avvengono attraverso la ricezione di un segnale di valutazione continuo, elaborato tramite complesse funzioni di perdita matematica (loss functions). Tra queste, il brevetto cita esplicitamente l’errore quadratico medio (Mean Squared Error) per le predizioni continue, l’entropia incrociata (Cross Entropy) per la classificazione categorica degli elementi dell’interfaccia, e la perdita cerniera (Hinge Loss) per l’ottimizzazione dei margini decisionali nei modelli di supporto vettoriale associati. Inoltre, l’architettura fa ampio e critico uso di tecniche di apprendimento per rinforzo basate su feedback umano (Reinforcement Learning from Human Feedback – RLHF) e sull’implementazione di modelli di ricompensa (Reward Models), i quali sono essenziali per affinare l’usabilità, la fluidità e la pertinenza psicologica delle interfacce utente generate.
Questo livello di sofisticazione tecnica e matematica indica in modo inequivocabile che l’obiettivo dell’infrastruttura non è semplicemente riassumere informazioni testuali provenienti da più fonti (come avveniva nelle iterazioni precedenti denominate AI Overviews o Search Generative Experience), ma sintetizzare e renderizzare intere architetture web interattive e navigabili che massimizzino il tasso di ingaggio dell’utente, colmando attivamente e bypassando i limiti strutturali, estetici o funzionali delle piattaforme sviluppate da terze parti.
Anatomia del “Landing Page Score”
Il meccanismo scatenante, l’interruttore algoritmico che innesca la generazione e la sostituzione della pagina web sintetica, è governato dal già citato “Landing Page Score”. L’introduzione di questo parametro rappresenta un’evoluzione ontologica e radicale rispetto ai tradizionali fattori di posizionamento SEO che hanno dominato l’industria per oltre due decenni.
Storicamente, i motori di ricerca hanno valutato l’autorità dei domini (tramite algoritmi derivati dal PageRank), la pertinenza semantica (attraverso l’analisi TF-IDF e, successivamente, i modelli transformer come BERT e MUM) e l’usabilità tecnica (attraverso le metriche dei Core Web Vitals come Largest Contentful Paint e Cumulative Layout Shift) al solo fine di determinare la posizione di un risultato all’interno di una lista ordinata. Il Landing Page Score, al contrario, agisce come un “Quality Gate” binario e assoluto: esso non determina la posizione, ma determina l’esistenza stessa della pagina all’interno del percorso di navigazione dell’utente. Se il punteggio fallisce, la pagina originale viene essenzialmente oscurata all’ultimo miglio.
Il calcolo computazionale di questo punteggio si fonda su un’aggregazione complessa e multidimensionale di metriche prestazionali, segnali comportamentali storici e valutazioni strutturali in tempo reale. L’analisi approfondita del documento rivela che il punteggio incorpora variabili sia strettamente quantitative che marcatamente qualitative.
Dal punto di vista quantitativo, il modello predittivo valuta metriche di ingaggio storiche e proiezioni statistiche, tra cui il tasso di conversione (Conversion Rate), la frequenza di rimbalzo (Bounce Rate) e la percentuale di clic (Click-Through Rate, CTR). L’inclusione esplicita del “tasso di conversione” come metrica discriminante all’interno di un brevetto di Information Retrieval solleva interrogativi tecnici profondi sulle metodologie di telemetria impiegate. È tecnicamente fondato dedurre che l’infrastruttura del motore di ricerca possa calcolare o stimare con estrema precisione l’efficacia conversazionale di un dominio triangolando i dati provenienti dall’ecosistema proprietario: l’uso del browser Chrome, le sessioni registrate su Google Analytics, le transazioni processate tramite Google Pay, i segnali comportamentali dei sistemi operativi Android e l’analisi dei pattern di pogo-sticking (il rapido ritorno dell’utente alla SERP dopo un clic insoddisfacente, forte indicatore di mancata conversione o insoddisfazione dell’intento).
Dal punto di vista qualitativo, strutturale e funzionale, il brevetto introduce criteri di valutazione che rasentano una vera e propria analisi architettonica dell’interfaccia utente. Il sistema analizza algoritmicamente la “qualità del design della pagina” e la “qualità del contenuto”. Ancor più dirompente è la capacità del modello di visione artificiale e di analisi del DOM (Document Object Model) di identificare specifiche “carenze funzionali” (Functional Deficiencies). Il testo brevettuale fornisce un esempio inequivocabile: il punteggio di penalizzazione supererà la soglia critica, innescando la sostituzione, se la landing page originale dell’e-commerce “manca di filtri per i prodotti”. Questa non è una valutazione semantica della pertinenza testuale, ma un’analisi euristica delle funzionalità di navigazione, dell’usabilità dell’inventario e dei percorsi di dettaglio del prodotto (product detail paths).
La formalizzazione matematica di questa logica decisionale può essere interpretata come un sistema di disuguaglianze in cui la sostituzione algoritmica ($S_{ai}$) si attiva se il deficit complessivo della pagina ($D_{lp}$) supera una soglia di tolleranza predefinita ($\tau$). Il deficit della landing page può essere modellizzato come una funzione di perdita composita:
Dove:
-
$C_{rate}$ rappresenta il tasso di conversione normalizzato.
-
$B_{rate}$ rappresenta la frequenza di rimbalzo storica per query simili.
-
$UI_{score}$ quantifica la qualità estetica e l’usabilità strutturale valutata tramite modelli di layout analysis.
-
$F_{def}$ è una penalità binaria o continua applicata in base all’assenza di funzionalità chiave (es. assenza di faceted search o filtri prodotto).
-
I coefficienti ($\alpha, \beta, \gamma, \delta$) rappresentano i pesi dinamici assegnati dal modello di machine learning in base al contesto della query.
Se $D_{lp} > \tau$, il sistema scarta il rendering dell’URL di destinazione e instrada l’utente verso il generatore di interfacce sintetiche. Questo approccio basato su soglie differisce intrinsecamente dal funzionamento tradizionale dei segnali di qualità, trasformando una valutazione di ranking incrementale in una decisione editoriale e strutturale di sostituzione.
La tabella seguente illustra la scomposizione teorica dei vettori di segnale che alimentano l’architettura del Landing Page Score, evidenziando il drastico passaggio da metriche SEO tradizionali a metriche orientate all’ottimizzazione dell’esperienza totale (Total Experience).
| Categoria del Segnale Algoritmico | Variabili Analizzate dall’Infrastruttura | Natura dell’Impatto sul Punteggio di Soglia |
| Metriche Comportamentali (Telemetry) | Frequenza di rimbalzo (Bounce rate), Pogo-sticking, Tempo di permanenza prima dell’uscita. | Elevato peso penalizzante per i tassi di abbandono prematuro o cicli di ricerca frustrati. |
| Metriche di Efficienza Transazionale | Tasso di conversione stimato o misurato, Fluidità dell’imbuto di conversione (funnel). | L’inefficienza commerciale o l’eccessivo attrito transazionale innesca la sostituzione predittiva. |
| Architettura Informativa e del DOM | Presenza/Assenza di filtri prodotto, Profondità dei percorsi di dettaglio, Complessità del codice. | L’assenza di elementi cruciali per la navigazione (es. faceted search) penalizza severamente il punteggio. |
| Ingegneria dell’Interfaccia Utente (UI) | Usabilità su dispositivi mobili, Chiarezza visiva delle Call-to-Action, Qualità del design estetico. | Valutazione basata su modelli di visione artificiale, rendering spaziale e layout analysis automatizzata. |
| Valutazione Semantica e di Contenuto | Rilevanza del contenuto testuale, Densità informativa rispetto all’intento di ricerca latente. | Verifica del perfetto allineamento tra la query complessa dell’utente e il contenuto effettivamente erogato. |
Le implicazioni di questo ecosistema valutativo sono sbalorditive.
Le organizzazioni digitali, i marchi e gli editori che possiedono un solido posizionamento organico ottenuto nel corso di anni, investendo in autorità dei domini, link building e ottimizzazione semantica, rischiano di vedere il proprio traffico azzerato all’ultimo miglio. Se l’interfaccia utente (UI) proprietaria non soddisfa gli standard di conversione, velocità e usabilità imposti algoritmicamente, l’utente non arriverà mai a visualizzarla. In scenari commerciali e di e-commerce, come chiaramente descritto e illustrato nelle figure allegate al brevetto, l’algoritmo prende una decisione del tutto autonoma di bypassare il sito originale, assemblando le informazioni e l’inventario per conto proprio, al fine esplicito di evitare attriti cognitivi o frustrazioni nel processo di ricerca e acquisto dell’utente.
Architettura della Generative UI: La Nascita delle Pagine Sintetiche
Una volta varcata la soglia critica del Landing Page Score, il sistema non si limita ad applicare un filtro o a generare un blocco di testo riassuntivo (come avveniva nelle primordiali iterazioni della intelligenza artificiale nella ricerca). Al contrario, istanzia un’interfaccia utente completa, dinamica, interattiva e iper-personalizzata. L’approfondimento della composizione tecnica di queste pagine web sintetiche rivela l’estensione e la potenza della tecnologia nota come “Generative UI”.
Il documento brevettuale descrive interfacce grafiche arricchite con componenti modulari che replicano, perfezionano ed evolvono le migliori funzionalità dei moderni siti di e-commerce e dei portali di informazione. Ogni singolo elemento della pagina subisce un processo di “Annotazione Dinamica” (Dynamic Annotation). Questo significa che il layout, l’ordine dei blocchi, le combinazioni cromatiche, i testi persuasivi e le posizioni degli elementi visivi non sono pre-renderizzati in un database statico, ma vengono calcolati e disposti in tempo reale sulla base della query specifica dell’utente e, cosa ancor più rilevante, del suo profondo contesto storico.
Tra le componenti interattive esplicitamente evidenziate nell’architettura brevettuale si trovano i feed di prodotti personalizzati. Questi forniscono una panoramica visiva, strutturata e altamente ottimizzata dell’inventario dell’organizzazione originale (presumibilmente attingendo a fonti di dati strutturati o feed di Merchant Center), arricchiti da titoli personalizzati (personalized headlines) concepiti e scritti dall’IA per massimizzare la risonanza psicologica con l’intento di ricerca specifico di quell’individuo in quel momento.
Le pagine sintetiche includono inoltre cluster di suggerimenti semantici per ampliare o restringere la ricerca, filtri adattivi che colmano dinamicamente le lacune strutturali del sito originale (fornendo, ad esempio, filtri per taglia, colore o fascia di prezzo che il sito del brand non aveva implementato correttamente), e pulsanti di chiamata all’azione (Call-to-Action) altamente performanti. Questi pulsanti indirizzano direttamente ai nodi di conversione o alle pagine di dettaglio dei prodotti (Sitelinks), saltando intere fasi del funnel di navigazione tradizionale.
Un elemento di rottura assoluta rispetto alle interfacce web tradizionali statiche è l’integrazione nativa e onnipresente di chatbot basati su intelligenza artificiale all’interno della landing page generata. Questo modulo conversazionale consente un’interazione fluida e continua, volta ad assistere l’utente nel processo decisionale, nell’esplorazione del catalogo o nella risoluzione di dubbi tecnici, agendo di fatto come un assistente alle vendite virtuale ospitato direttamente sull’infrastruttura del motore di ricerca.
Il Ruolo del User Content Profile (UCP) e le Radici Algoritmiche
Questa sbalorditiva capacità di architettura in tempo reale non nasce dal nulla, ma si appoggia fortemente su costrutti tecnologici e di raccolta dati consolidati nel corso di decenni e formalizzati in brevetti precedenti, in particolare quelli relativi al concetto di “User Content Profile” (Profilo di Contenuto dell’Utente – UCP). L’analisi della letteratura tecnica storica del motore di ricerca evidenzia come l’adattamento contestuale estremo sia un obiettivo ingegneristico perseguito fin dagli albori della personalizzazione del web.
Brevetti antecedenti e fondamentali per comprendere l’attuale evoluzione (come il brevetto US5867799A) descrivevano meccanismi sofisticati per l’acquisizione continua di micro-unità di informazione (definite “informons”) e la costruzione di complesse reti di filtraggio collaborativo (collaborative filtering) basate sui feedback adattivi degli utenti nel tempo. In quei modelli algoritmici storici, il profilo di un individuo veniva costantemente aggiornato e raffinato elaborando le interazioni passate, il tempo di lettura, i clic e le valutazioni implicite, creando un UCP denso di dati. Questo profilo veniva poi utilizzato per raccomandare articoli semanticamente rilevanti, mescolando l’analisi semantica pura del testo (content-based filtering) con il filtraggio collaborativo su larga scala, ovvero suggerendo contenuti che utenti con profili simili avevano trovato utili.
Oggi, quell’infrastruttura di profilazione latente e immensamente vasta viene innestata direttamente nei prompt di sistema e nei contesti di inferenza dei Grandi Modelli Linguistici (LLM). Quando il brevetto US12536233B1 menziona in modo apparentemente innocuo l’utilizzo di “informazioni contestuali (come le query precedenti)” per addestrare il modello a elaborare e generare la pagina personalizzata, si riferisce all’evoluzione diretta e alla massimizzazione di queste architetture UCP.
Il motore di ricerca, grazie a decenni di accumulo dati, possiede la topologia completa delle preferenze di un utente, la sua propensione all’acquisto per specifiche categorie merceologiche, la sua sensibilità ai prezzi, il suo livello di alfabetizzazione tecnica su un argomento e i suoi schemi di navigazione preferiti. La tecnologia di Generative UI descritta nel nuovo brevetto si limita a tradurre questo vasto e profondo database psicografico in un’interfaccia DOM temporanea, fluida e irripetibile, che si adatta come un guanto alla psiche dell’individuo in quell’esatto istante di ricerca.
L’Ecosistema AI 2025-2026: Gemini 3, AI Mode e la Ricerca Agentica
La concessione del brevetto US12536233B1 non è un evento tecnico isolato, ma rappresenta un tassello cruciale e convergente all’interno di una strategia infrastrutturale molto più ampia, accelerata esponenzialmente tra il 2024 e i primi mesi del 2026. La comprensione profonda di questo fenomeno generativo richiede la sua contestualizzazione all’interno delle recenti e tumultuose evoluzioni dei modelli proprietari, come dettagliatamente documentato negli annunci ufficiali e nelle comunicazioni istituzionali sui progressi della ricerca.
Nel novembre 2025, è stata ufficialmente annunciata al mondo la capacità di “Generative UI”, descritta come un’esperienza utente visiva, ricca, personalizzata e interattiva, creabile su misura a partire da qualsiasi prompt testuale o intento implicito. Questa straordinaria capacità è stata integrata nelle fondamenta stesse del modello Gemini 3, lanciato contestualmente. L’arrivo di Gemini 3 ha introdotto un’era tecnologica definita non più dalla semplice predizione statistica delle parole successive, ma dal “ragionamento” (reasoning) avanzato, dalla pianificazione a lungo termine e dall’uso autonomo di strumenti software complessi (tool calling).
Gemini 3 ha dimostrato, attraverso benchmark rigorosi, capacità eccezionali nella generazione zero-shot (senza esempi pregressi) di interfacce utente web complesse, gestendo istruzioni articolate per renderizzare simulazioni visive e layout immersivi direttamente all’interno della SERP. Questa modalità operativa, ribattezzata commercialmente “AI Mode”, rappresenta il motore logico dietro l’implementazione del brevetto in esame.
L’introduzione della modalità AI Mode nella ricerca online segna il passaggio definitivo da un sistema di interrogazione reattiva (l’utente chiede, il motore elenca) a un framework di pianificazione proattiva e agentica. Attraverso l’utilizzo di una sofisticata tecnica algoritmica definita “query fan-out”, il sistema non si limita più a recuperare documenti preesistenti da un indice invertito. Al contrario, mette in atto un piano di ricerca esplorativo autonomo: formula sotto-query per espandere il contesto, consulta basi di dati strutturate proprietarie (come il massiccio Knowledge Graph o il Merchant Center), analizza i risultati testuali e visivi in tempo reale, ed estrae le entità rilevanti. Il modello acquisisce informazioni complesse da fonti multiple e frammentate, per poi sintetizzarle in layout visivi dinamici e navigabili, generati sul momento.
L’architettura del brevetto beneficia enormemente dello sviluppo parallelo di SDK per agenti autonomi (come l’evoluzione del framework open-source Swarm e le piattaforme proprietarie come Google Antigravity) e dell’integrazione di strumenti specializzati come il “Web Search Tool” (per il recupero di dati verificati in tempo reale) e il “Computer Use Tool”. Quest’ultimo, in particolare, permette agli agenti di intelligenza artificiale di eseguire azioni complesse in ambienti grafici legacy e di interagire con interfacce progettate per gli esseri umani, automatizzando l’estrazione di dati persino da siti web privi di API strutturate.
Ancor più affascinante, e indicativo della traiettoria futura, è lo sviluppo della “IA fisica” attraverso iniziative collegate come Gemini Robotics (Gemini for the Physical) e Project Astra, che traducono l’incredibile capacità di ragionamento multimodale in elaborazione di flussi video in tempo reale e nella generazione di azioni concrete nel mondo tridimensionale.
In questo contesto macroscopico di convergenza tecnologica, la pagina web generata dall’AI descritta dal brevetto US12536233B1 cessa di essere percepita come una semplice “pagina web migliore” o un esperimento di design. Essa agisce, a tutti gli effetti, come un terminale temporaneo e interattivo di un agente autonomo superiore. Questo agente esamina il fornitore di servizi o il marchio (il sito web originale), lo giudica inadeguato rispetto ai propri rigidi parametri di conversione, acquisisce il suo inventario disaggregato, e negozia l’esperienza direttamente con l’utente finale attraverso un’interfaccia sintetica ottimizzata spietatamente per il cervello specifico di quell’utente. Il “Context Engineering” (l’ingegneria del contesto) diventa così la vera e unica leva competitiva del futuro.
Cosa cambia lato SEO?
L’implementazione su scala globale di questa architettura algoritmica solleva implicazioni telluriche e destabilizzanti per l’intera industria del digital marketing, per i professionisti dell’ottimizzazione per i motori di ricerca (SEO) e, in modo ancor più grave, per l’economia di base dell’editoria online e dell’e-commerce indipendente. Un’analisi critica del panorama attuale, alimentata dalle reazioni degli addetti ai lavori e dagli specialisti del settore, evidenzia un clima di profonda preoccupazione strutturale, unita all’ineludibile fascino per l’eleganza ingegneristica della soluzione.
La prima e più devastante conseguenza economica di questo paradigma è lo spostamento massiccio e irreversibile del traffico organico. Il fenomeno storico e ampiamente dibattuto delle “Zero-Click Searches” (ricerche che si esauriscono all’interno della SERP senza generare alcun traffico in uscita, a causa della presenza di Knowledge Panel, Featured Snippets o risposte generate dall’AI) è destinato a evolversi in un concetto commerciale ben più letale per i marchi: le “Zero-Click Conversions”.
Se l’utente finale esplora il catalogo di un’azienda, interagisce con il chatbot per chiarire le specifiche di un prodotto, seleziona le varianti desiderate e, potenzialmente, finalizza la scelta direttamente sull’infrastruttura del motore di ricerca tramite un’interfaccia Generative UI, il sito web dell’inserzionista o del brand viene completamente svuotato della sua fondamentale funzione relazionale, persuasiva ed esperienziale. Il sito istituzionale viene ridotto a un mero database logistico e di stoccaggio operativo in background, un fornitore di API non retribuito per l’agente AI.
Questa dinamica genera problematiche colossali e difficilmente risolvibili relative al controllo dell’identità di marca (Brand Control) e alla trasparenza dell’attribuzione (Attribution Transparency). Da decenni, l’identità visiva, il posizionamento semantico, la psicologia dei colori e la voce del marchio (Tone of Voice) sono controllati meticolosamente dalle aziende attraverso il design dell’interfaccia utente e i percorsi narrativi delle proprie landing page. Se un algoritmo asettico decide autonomamente di sovrascrivere questa interfaccia curata perché non la ritiene sufficientemente ottimizzata per le proprie metriche di conversione a breve termine , l’azienda perde istantaneamente il suo veicolo di comunicazione e differenziazione primario.
Inoltre, la sottrazione fisica della sessione utente al dominio originario impedisce l’attivazione dei pixel di tracciamento di terze parti, il caricamento degli script delle piattaforme di web analytics e il deposito dei cookie di prima parte. Questo mutile le capacità di remarketing, la segmentazione dell’audience, la profilazione avanzata e la gestione delle relazioni con i clienti (Customer Relationship Management – CRM) su cui si basa l’intera economia del marketing digitale moderno. L’attribuzione del valore diventa un buco nero, gestito esclusivamente dai report forniti dall’infrastruttura che ha generato la pagina sintetica.
Un aspetto del documento brevettuale che ha scosso profondamente gli analisti e che merita un’attenzione critica particolare è contenuto nella formulazione della rivendicazione 2 (Claim 2). Il testo legale del brevetto specifica in modo inequivocabile che la pagina generata dall’intelligenza artificiale, costruita raccogliendo informazioni e assemblando layout per rispondere alla query di un determinato marchio (Brand A), “può essere presentata a un’altra organizzazione che è diversa dalla prima organizzazione” e “può essere utilizzata per future ricerche”.
Le implicazioni anti-competitive e commerciali di questa singola clausola sono sbalorditive. Significa che una pagina sintetica, altamente performante e persuasiva, originariamente modellata dall’algoritmo per compensare le carenze UX di un inserzionista specifico, potrebbe essere memorizzata nei tensori del modello, generalizzata nei suoi principi di design, e servita a un utente che ricerca un prodotto concorrente (Brand B) in un momento successivo. Si crea di fatto un ecosistema di interfacce fluide, liquide e agnostiche rispetto al brand proprietario dei dati, in cui le migliori pratiche di conversione estratte da un attore del mercato vengono usate per ottimizzare le vendite dei suoi concorrenti all’interno del “walled garden” (giardino recintato) del motore di ricerca.
La reazione dell’industria SEO a questo paradigma incombente è passata dalla negazione e dall’incredulità iniziale all’analisi strategica pragmatica e difensiva. L’aspetto più allarmante sottolineato dall’analisi critica è che il sistema descritto non richiede il consenso dell’inserzionista (Opt-in), né l’approvazione del webmaster, né la stipula di un accordo commerciale per generare e sostituire la landing page. Il meccanismo computazionale prende decisioni editoriali e commerciali in maniera totalmente autonoma e unilaterale, basandosi esclusivamente sui propri modelli di efficienza pre-addestrati e sul superamento matematico della famigerata soglia del Landing Page Score. Questo passaggio trasforma definitivamente il motore di ricerca da un indicizzatore neutrale di risorse pubbliche a un aggregatore, sintetizzatore e arbitro supremo delle risorse aziendali, incrementando vertiginosamente e pericolosamente la dipendenza degli inserzionisti e degli editori dall’ecosistema proprietario della piattaforma. Il rischio sistemico di disintermediazione non è mai stato così elevato nella storia del web commerciale.
L’Ingegneria della Sopravvivenza nel Web Sintetico
Alla luce di questa imponente e pervasiva architettura algoritmica, l’ottimizzazione per i motori di ricerca (SEO) tradizionale cessa di esistere nella sua forma classica. Non può più essere concepita esclusivamente come l’ottimizzazione chirurgica dei segnali di scansione (crawl budget), indicizzazione, e rilevanza testuale basata su parole chiave. L’avvento imminente delle AI-Generated Landing Pages richiede una ricalibrazione totale della disciplina, in cui la User Experience (UX), la Performance Engineering e la Conversion Rate Optimization (CRO) convergono per formare l’unica vera linea di difesa contro l’obsolescenza e l’estromissione algoritmica dal percorso dell’utente.
Per preservare l’integrità del proprio traffico organico, mantenere il controllo sul proprio marchio ed evitare a tutti i costi l’innesco della Generative UI sostitutiva, i webmaster, gli architetti dell’informazione e i professionisti del marketing digitale devono focalizzarsi in modo quasi ossessivo sull’elusione del Landing Page Score negativo. Se la penalizzazione matematica scatta primariamente in presenza di colli di bottiglia cognitivi, rallentamenti prestazionali o carenze strutturali palesi , la strategia di mitigazione tecnica deve concentrarsi sui seguenti pilastri ingegneristici e di design avanzato:
1. Ottimizzazione Estrema della Frizione Transazionale e Prestazionale
Il tasso di rimbalzo (Bounce Rate), le metriche di abbandono del carrello e i tempi di sessione brevi non sono più meri indicatori di business analysis da discutere nei report trimestrali; sono diventati fattori di rischio algoritmico acuto e immediato. I percorsi utente (user journey) devono essere snelliti in modo spietato. La velocità di rendering del lato client (Client-Side Rendering) e l’interattività del codice JavaScript (misurata tramite metriche avanzate e severe come l’Interaction to Next Paint – INP) devono avvicinarsi alla perfezione tecnica assoluta. L’obiettivo è segnalare inequivocabilmente ai modelli di machine learning telemetrici che il sito proprietario offre un’esperienza così fluida e priva di attriti che non necessita in alcun modo di una sostituzione sintetica. Qualsiasi elemento di distrazione visiva, pop-up intrusivo o ritardo nel caricamento del DOM potrebbe far superare la soglia del deficit ($D_{lp} > \tau$).
2. Architettura dell’Informazione e Funzionalità Strutturali Impeccabili
Come esplicitato in modo allarmante nel testo del brevetto, l’assenza di percorsi di esplorazione logici, rapidi e granulari, come i filtri di prodotto (faceted search) o le opzioni di ordinamento chiare , viene interpretata dall’algoritmo visivo come una “carenza funzionale” critica e invalidante. Le piattaforme di e-commerce e i grandi portali informativi devono implementare una navigazione a faccette tecnicamente perfetta, supportata da schemi di tassonomia profondi e gerarchicamente ineccepibili. Queste funzionalità non devono solo esistere visivamente, ma devono essere esposte chiaramente ai bot di scansione e ai moduli di comprensione semantica attraverso una struttura DOM leggibile, semanticamente corretta (HTML5) e priva di ostacoli basati su framework JavaScript non renderizzabili. Se l’utente non può filtrare il catalogo in tre clic, l’AI lo farà per lui, su un altro dominio.
3. Profonda Integrazione Semantica e Dati Strutturati Onnipresenti
Se si accetta il postulato che il motore di ricerca è ormai in grado di estrarre l’inventario per costruire interfacce sintetiche alternative tramite feed di prodotti, l’architettura dei feed stessi (ad esempio tramite la sincronizzazione impeccabile con Google Merchant Center) e l’implementazione maniacale dei dati strutturati (Schema.org) sulle pagine dei prodotti e degli articoli diventano il “livello zero” della visibilità digitale. Anche qualora l’azienda dovesse perdere la battaglia UX e subire l’onta di non ospitare la sessione utente originale, l’accuratezza semantica granulare dei dati del prodotto (disponibilità in tempo reale, variazioni di prezzo, recensioni strutturate, specifiche tecniche) garantirà perlomeno che i propri beni vengano presentati correttamente, con il prezzo giusto e le informazioni aggiornate, all’interno della pagina autogenerata dal motore. Essere un database perfetto diventa il piano B obbligatorio.
4. Costruzione di Esperienze Esclusive e In-Sintetizzabili (Un-synthetic UX)
Poiché un modello LLM, per quanto titanico e avanzato come Gemini 3, genera layout e contenuti basandosi su pattern probabilistici appresi da enormi volumi di dati storici , l’unico modo per differenziare a lungo termine il proprio ecosistema è offrire esperienze che l’intelligenza artificiale, per sua stessa natura generativa e matematica, non può sintetizzare dinamicamente in tempo reale. Questo approccio filosofico e pratico include lo sviluppo di logiche di gamification complesse, integrazioni di Realtà Aumentata e Virtuale (AR/VR) che richiedono interazioni fisiche, la costruzione di community chiuse e fortemente identitarie attorno al brand, programmi fedeltà profondamente intrecciati nell’UX, e uno storytelling audiovisivo interattivo ad altissima fedeltà. Queste esperienze creano un “fossato difensivo” (moat) che va ben oltre la capacità di rendering immediato dei “Computer Use Tools” o dei generatori di layout automatizzati. L’obiettivo è far sì che la query dell’utente diventi di natura puramente navigazionale (“Voglio andare esattamente su quel sito perché l’esperienza lì è unica”), annullando l’intento transazionale generico che innesca la sostituzione AI.
Il futuro digitale dipinto dalle analisi sulle nuove funzionalità e sulle capacità di “reasoning” (AI Mode e l’evoluzione di Gemini Robotics) evidenzia una dicotomia netta e inesorabile per il prossimo decennio. Da un lato, le transazioni banali, le ricerche puramente informative, la comparazione basica di prezzi e l’acquisto di beni di prima necessità (commodity) saranno quasi interamente gestite, re-impaginate e risolte da agenti virtuali e interfacce sintetiche ospitate dal motore di ricerca, annullando il traffico verso i siti intermediari deboli. Dall’altro lato, i domini web proprietari dovranno trasformarsi in destinazioni digitali premium, architetture complesse simili a flag-ship store nel mondo fisico, dove gli utenti decidono consapevolmente e volontariamente di atterrare per un’esperienza di marca profonda, relazionale e immersiva, sfuggendo deliberatamente alla comodità standardizzata della Generative UI.
L’Alba Inevitabile del Web Sintetico
In sintesi, l’analisi tecnica ed esaustiva dell’architettura descritta nel brevetto US12536233B1, unita allo studio dell’ecosistema circostante di intelligenza artificiale sviluppato tra il 2024 e il 2026, rivela un punto di inflessione epocale nella storia della rete internet e delle architetture dell’informazione. Il drammatico passaggio dalla semplice fornitura di link ipertestuali all’orchestrazione proattiva delle conversioni umane tramite interfacce Generative UI rappresenta la massima e più aggressiva espressione di una tecnologia matura, decisa a interiorizzare e monopolizzare l’intera catena del valore digitale.
Il calcolo spietato, matematico e apparentemente oggettivo del “Landing Page Score” agisce come un inesorabile setaccio evolutivo darwiniano. I siti web che hanno storicamente funto esclusivamente da contenitori approssimativi per merci fisiche, arbitraggio di affiliazioni o informazioni banali, gravati da design obsoleti, architetture lente o percorsi utente frammentati, sono inevitabilmente destinati all’oblio algoritmico. Verranno sostituiti, silenziosamente e in tempo reale, da architetture sintetiche iper-personalizzate, macchine di conversione perfette in grado di interpretare, mappare e sfruttare il User Content Profile del consumatore con una precisione che nessun webmaster umano potrebbe mai eguagliare.
Le preoccupazioni espresse a gran voce dalla comunità tecnica, dagli analisti SEO e dagli editori riguardo alla perdita di controllo del brand, al disallineamento fatale dei dati di attribuzione e all’aumento vertiginoso della dipendenza dagli ecosistemi chiusi delle corporazioni tecnologiche (Big Tech) sono profondamente fondate e rappresentano emergenze di settore immediate. Tuttavia, il processo di transizione appare storicamente irreversibile, trainato non solo dall’ambizione tecnologica, ma dall’inesorabile domanda del mercato e dei consumatori per interazioni fluide, istantanee e cognitive zero-friction. Questo desiderio è ora tecnicamente sostenuto da modelli di architettura multi-agente e capacità di ragionamento autonomo (come brillantemente dimostrato dai benchmark di Gemini 3 e dalla fluidità della AI Mode) che superano in ordini di grandezza le capacità di rendering statico e di personalizzazione di innumerevoli piattaforme indipendenti messe insieme.
L’era dell’AI-Generated Content Page impone ai brand commerciali, agli editori, agli strateghi SEO e agli architetti dell’informazione di elevare i propri standard ingegneristici e creativi ben oltre la semplice sufficienza tecnica e funzionale. Il World Wide Web del prossimo decennio sarà un ambiente profondamente mediato da intelligenze artificiali che agiranno da guardiani dell’attenzione e dell’intento. In questo nuovo ecosistema sintetico, sopravviveranno, e manterranno la propria indipendenza economica, solo coloro che riusciranno a fondere la perfezione tecnica assoluta (evitando i mortali trigger negativi di sostituzione algoritmica) con un valore esperienziale intrinsecamente umano, narrativamente profondo e, soprattutto, matematicamente non sintetizzabile. L’innovazione tecnologica ha definitivamente dischiuso una realtà in cui l’algoritmo non si limita più a valutare l’attinenza di una risposta a una domanda, ma assume la regia totale dell’intera esperienza cognitiva e transazionale dell’utente, costringendo il mercato globale a una rapida, drastica e imperativa ricalibrazione strategica per la sopravvivenza.
fonti:https://patents.google.com/patent/US5867799A/en https://patents.google.com/patent/US11663201B2/en https://patents.google.com/patent/US20110271007
