
Negli ultimi giorni, la community SEO internazionale ha discusso animatamente su un’apparente contraddizione nelle specifiche di Google: prima si parlava di un limite infrastrutturale di 15MB, oggi si punta il dito sui 2MB.
In realtà, non stiamo assistendo a un semplice “taglio” delle risorse, ma a una separazione architetturale molto più netta tra due fasi distinte del processo di acquisizione dati.
Approfondiamo perché questo limite esiste, perché non dovrebbe spaventarti (a meno che tu non abbia un sito mal configurato) e come gestirlo a livello avanzato.
Due limiti, due scopi: Facciamo chiarezza
È fondamentale distinguere tra la capacità della rete di Google e le regole specifiche del bot di ricerca.
A) Il limite “Infrastrutturale” (15MB)
Per impostazione predefinita, l’infrastruttura di crawling generica di Google (quella che gestisce il fetch a basso livello) considera i file fino a 15MB.
-
Cosa succede oltre: Tutto ciò che eccede questa soglia viene brutalmente troncato o ignorato a livello di rete.
-
Scopo: Protezione contro attacchi DoS, loop di reindirizzamento infiniti o download di file binari mostruosi scambiati per testo.
B) Il limite “Applicativo” per Search (2MB)
Quando il crawling è finalizzato specificamente a Google Search (indicizzazione web), Googlebot applica una regola più stringente: scarica e processa i primi 2MB di un file testuale (HTML, TXT).
-
L’eccezione PDF: Per i documenti PDF, il limite è più generoso, arrivando fino a 64MB (poiché i PDF contengono intrinsecamente più overhead binario).
Dettagli tecnici critici:
-
Uncompressed is King: Il limite si applica ai dati non compressi. Anche se il tuo server invia un file GZIP di 300KB, se decomprimendolo diventa 2.5MB, Googlebot ne leggerà solo i primi 2MB.
-
Fetch Atomico delle Risorse: Ogni risorsa referenziata (CSS, JS, Immagini) viene fetchata con una richiesta HTTP separata. Il limite di 2MB riguarda il singolo documento HTML principale, non la somma delle risorse della pagina.
-
Il Cutoff: Raggiunti i 2MB, Googlebot interrompe lo stream. Quello che è arrivato passa all’indicizzazione/rendering; il resto è perso nel vuoto.
Approfondimento: Consulta la documentazione ufficiale di Google sui limiti di crawling per i dettagli aggiornati sui tipi di file supportati.
Perché 2MB sono un’enormità
Se guardiamo al web reale, 2MB di puro codice HTML (testo) sono un valore aberrante. Per capire quanto sia alto questo “soffitto”, confrontiamo i dati del Web Almanac con il limite di Google.
Dimensioni HTML vs Limite Googlebot
Dati basati su mediane globali HTTP Archive (Web Almanac 2024)
| Metrica | Dimensione Tipica (Mediana) | 90° Percentile (Siti pesanti) | Limite Googlebot (HTML) | Note |
| Transfer Size (Compresso) | ~32-33 kB | ~148 kB | N/A | Ciò che viaggia sulla rete. |
| Decoded Size (Decompresso) | ~150-200 kB | ~800 kB | 2.000 kB (2MB) | Ciò che vede Googlebot. |
| Margine di sicurezza | Enorme | Ampio | 0 (Cutoff) | Anche i siti pesanti sono spesso sotto 1MB. |
Conclusione pratica: Il limite dei 2MB non è una “nuova normalità” a cui adattarsi, ma un guardrail di sicurezza. Serve a evitare che Googlebot sprechi risorse computazionali su pagine patologiche, generate male o vittime di bug lato server.
Google usa LLM per il crawling?
La riduzione/chiarimento sui 2MB ha fatto pensare a molti: “Google sta risparmiando token perché ora legge le pagine con le AI (LLM)?”.
Sebbene suggestiva, questa ipotesi è tecnicamente imprecisa.
-
Il costo del Rendering (WRS): Il vero collo di bottiglia non è tanto la lettura del testo, ma il Web Rendering Service. Parsare un DOM (Document Object Model) di 5MB richiede molta più CPU e memoria di uno di 100KB. Il limite serve a proteggere la pipeline di rendering, non (solo) quella semantica.
-
Google-Extended: Per l’addestramento dei modelli AI (Gemini/Vertex), Google ha introdotto user-agent e token specifici (
Google-Extended). -
Pipeline separata: È molto probabile che Google utilizzi modelli leggeri per l’estrazione, ma il limite di 2MB risponde a una logica di ingegneria dei sistemi (riduzione costi e latenza) più che a una logica puramente AI-driven.
L’Impatto SEO Reale: Quando il “Cutoff” diventa un disastro
Se il tuo HTML non compresso supera i 2MB, il problema non è solo “perdo il footer”. Le implicazioni tecniche sono subdole e possono distruggere la visibilità organica. Ecco i 4 rischi maggiori:
1. Indicizzazione Parziale (Thin Content involontario)
Googlebot indicizza solo ciò che ha scaricato. Se il contenuto principale (main content) inizia dopo tonnellate di codice boilerplate, CSS inline o SVG inline, potresti finire con una pagina che agli occhi di Google appare vuota o di scarsa qualità.
2. Cecità sui Dati Strutturati (JSON-LD interrotto)
Questa è la causa più frequente di errori nei Rich Snippet. Molti plugin o sviluppatori inseriscono lo script application/ld+json nel footer per non bloccare il rendering.
-
Scenario: Il file viene troncato a 2MB.
-
Risultato: Il blocco JSON si interrompe a metà (manca la
}di chiusura). -
Conseguenza: Errore di sintassi. L’intero pacchetto di dati strutturati viene invalidato e ignorato. Addio review stars, product schema o breadcrumbs.
3. Link Discovery compromessa
I link interni sono le arterie del tuo sito. Spesso i link ai prodotti correlati, al footer o alle categorie secondarie si trovano alla fine del DOM. Se troncati, Googlebot non scoprirà quelle URL (o perderanno la link equity interna), creando problemi di orfani e cattiva distribuzione del crawl budget.
4. Il Paradosso del Rendering (JS e Hydration)
Googlebot scarica CSS e JS separatamente, ma se il tuo HTML iniziale contiene enormi stati di “Hydration” (tipico di Next.js/React/Nuxt) per far funzionare quel JS, stai consumando il budget dei 2MB proprio con dati che non sono contenuto visibile, ma stringhe JSON.
Diagnostica Avanzata: Sei a rischio?
Non affidarti solo al “peso del file” che vedi sul desktop (spesso compresso). Ecco come misurare come un ingegnere.
Metodo A: Terminale
Usa curl per simulare la richiesta e contare i byte effettivi del body decompresso.
# Sostituisci con il tuo URL.
# -s : silent mode
# -L : segue i redirect
# --compressed : scarica compresso (come fa Google) ma decomprime in output
curl -sL --compressed "https://tuo-sito.com/pagina-critica" | wc -c
-
Risultato: Se il numero è vicino a
2000000(2 milioni di byte), sei in zona rossa.
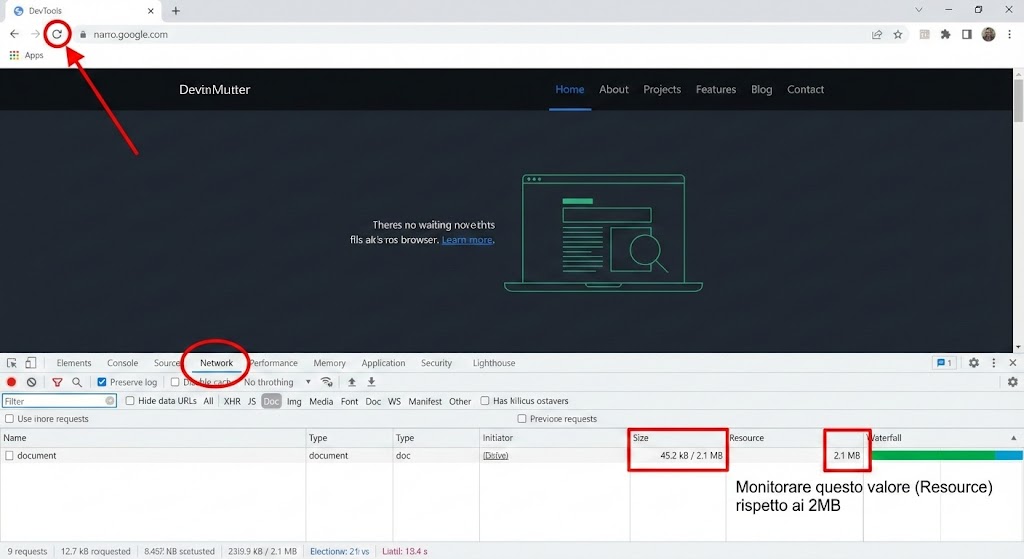
Metodo B: Chrome DevTools
-
Apri la pagina in Chrome.
-
Tasto destro -> Ispeziona -> Tab Network.
-
Ricarica la pagina.
-
Filtra per Doc.
-
Guarda le colonne Size (trasferito) e Resource (decompresso).
-
È il valore sotto Resource che devi monitorare rispetto ai 2MB.
-
Metodo C: Log Analysis
Nei log del server, cerca richieste di Googlebot che hanno un bytes_sent sospettosamente costante e vicino ai 2MB, o connessioni chiuse prematuramente. Se noti un pattern dove Googlebot scarica sempre esattamente 2.097.152 bytes (2MB esatti) su certe pagine, sta avvenendo un troncamento.
Le 5 Cause di “Obesità HTML”
Analizzando siti enterprise, il 99% dei problemi deriva da queste fonti:
1) Hydration State (Il colpevole #1 nelle SPA/SSR)
Framework come Next.js o Nuxt iniettano lo stato dell’applicazione in un tag <script> (es. window.__NEXT_DATA__) per permettere al client di “riprendere” l’interattività.
-
Sintomo: Blocchi di JSON enormi nel codice sorgente che duplicano il contenuto visibile.
-
Soluzione Avanzata: Usa tecniche di “Partial Hydration” o “Island Architecture” (es. Astro). Evita di passare props giganti che non servono al rendering iniziale. Pulisci i dati API prima di passarli al componente di pagina.
2) Immagini in Base64
-
Sintomo:
<img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAA...">. -
Problema: Il Base64 aumenta la dimensione del file del ~33% rispetto al binario. Se includi immagini inline nell’HTML, mangi spazio prezioso.
-
Soluzione: Usa URL esterni standard per le immagini. Riserva il Base64 solo per icone minuscole (sotto 1KB) critiche per il LCP.
3) CSS Inlining Incontrollato “Critical Path”
-
Sintomo: Strumenti automatici che inlinano tutto il CSS “above the fold” finendo per inlinare 500KB di stili.
-
Soluzione: Sii parsimonioso. Inlina solo lo stretto necessario per il rendering dell’header e della hero section. Il resto va in un file
.cssesterno (che viene cachato e fetchato a parte).
4) Mega-Menu e DOM Explosion
-
Sintomo: L’HTML contiene il codice per 500 link di menu, 40 modali nascoste e 20 popup, tutti presenti nel DOM al caricamento ma nascosti via CSS (
display: none). -
Soluzione: Usa il pattern content-visibility o carica le parti non visibili (modali, mega menu complessi) tramite fetch JavaScript all’interazione dell’utente (on hover/click).
5) Commenti e ViewState
-
Sintomo: Pagine ASP.NET vecchie con
__VIEWSTATEchilometrici o sviluppatori che lasciano codice commentato in produzione. -
Soluzione: Minificazione aggressiva dell’HTML in build pipeline per rimuovere commenti e spazi bianchi. Disabilita ViewState se non necessario.
Best Practice SEO
Per dormire sonni tranquilli, adotta questa strategia di priorità nel codice (DOM Order):
-
Top 100KB :
-
<title>, Meta tags. -
<head>pulito. -
JSON-LD Dati Strutturati Critici (Prodotto, Articolo, Breadcrumb). Spostali nella head, non nel footer.
-
Navigazione principale.
-
<h1>e primo paragrafo del contenuto.
-
-
Entro 1MB:
-
Tutto il contenuto testuale principale.
-
Immagini principali (tag
img).
-
-
Zona a Rischio (>1.5MB):
-
Script di tracciamento terze parti (se non gestiti via GTM).
-
Footer secondari.
-
Widget correlati “infiniti”.
-
Nota Strategica: Tratta i 2MB come un bug bloccante. Se ti avvicini a questa soglia, non ottimizzare per “stare dentro”, ma rifattorizza il template. Un HTML così pesante è quasi sempre indice di cattive performance per l’utente (Core Web Vitals), non solo per il bot.
Niente panico: ma serve anche la SEO tecnica
Il limite “2MB per Google Search” non significa che Google è diventato “cieco”. Significa che è diventato intollerante agli sprechi.
È un limite ragionevole che non tocca il 99% dei siti ben costruiti. Ma se gestisci e-commerce complessi, siti in Next.js/SSR o portali legacy, questo è il momento di fare un audit tecnico del decoded HTML size.
Hai dubbi? Chiedi una nostra consulenza SEO Avanzata!
