Se nel 2026 state ancora inviando ai vostri clienti report con scritto “Siamo in prima posizione per la keyword X”, state, tecnicamente parlando, mentendo. O meglio, state raccontando una verità parziale che non regge alla prova dell’architettura dei moderni motori di ricerca.
Un recente studio analizzato da Search Engine Land ha scoperchiato il vaso di Pandora: le liste di raccomandazione generate dalle AI (ChatGPT, Gemini, SGE/AI Overviews) si ripetono meno dell’1% delle volte. Significa che se chiediamo 100 volte a un LLM “Quali sono i migliori software CRM?”, otterremo quasi 100 permutazioni diverse. Alcuni brand appaiono, poi scompaiono, poi riappaiono in ordine diverso.
Molti SEO gridano al “caos” o al “bug”. Io vi dico che non è un bug. È una feature. Ed è spiegabile matematicamente analizzando i brevetti di Google e la termodinamica degli LLM.
Oggi facciamo quello che ci piace fare in DeepSEO e in YourdigitalWeb: apriamo il cofano, ci sporchiamo le mani con le formule e analizziamo il brevetto US 11,769,017 B1.
1. Il Mito della Ripetibilità: I Dati
Lo studio evidenzia un cambio di paradigma brutale. Nei motori di ricerca classici (Information Retrieval deterministico), l’algoritmo è stabile: a parità di input e condizioni utente, l’output è identico. $f(x) = y$.
Nei motori generativi (Generative Information Retrieval), l’output è probabilistico. $P(y|x)$.
Il fatto che le liste di raccomandazione varino nel 99% dei casi distrugge il concetto di “Ranking Fisso”. Non esiste più il posto fisso nella SERP. Esiste una lotta per la probabilità di campionamento. Ma perché succede? Per capirlo dobbiamo scendere nel livello matematico che governa la generazione del testo.
La Matematica dell’Incertezza: Softmax e Temperatura
Un Large Language Model non “sceglie” la risposta migliore in assoluto. Calcola la probabilità del prossimo token (parola/concetto) basandosi sul contesto precedente.
Se il modello usasse sempre la funzione argmax (scegliendo sempre la parola con la probabilità più alta), le risposte sarebbero robotiche e ripetitive. Per questo, i motori implementano il Campionamento (Sampling) controllato da un parametro chiamato Temperatura ($T$).
La probabilità $P(x_i)$ che il tuo brand (o il tuo contenuto) venga scelto e menzionato dall’AI è governata dalla funzione Softmax con Temperatura:
Dove:
-
$z_i$ è il logit: il punteggio grezzo di rilevanza che il modello assegna alla tua entità (basato sulla tua autorità, semantica, menzioni, ecc.).
-
$T$ è la Temperatura: un parametro che controlla l’entropia (il “caos” o la “creatività”).
-
$\exp$ è la funzione esponenziale di Nepero.
Cosa significa per la SEO?
Se $T$ fosse 0, vincerebbe sempre chi ha il logit $z$ più alto (il vecchio “primo posto”).
Ma nei task generativi (come “scrivi una lista dei migliori prodotti”), $T è sempre > 0$.
Questo introduce una varianza stocastica. Anche se il vostro sito è tecnicamente “il migliore” (ha il $z_i$ più alto), c’è una probabilità statistica non nulla che il modello “peschi” un competitor con un punteggio leggermente inferiore, semplicemente a causa del sampling noise.
Analisi del Brevetto Google US 11,769,017 B1
Per confermare che questa non è solo teoria accademica, ho analizzato il brevetto “Generative summaries for search results” (Assegnatario: Google LLC). Questo documento è la blueprint di come funziona AI Overviews. Ecco due diagrammi fondamentali estratti dal brevetto che spiegano il processo.
Il Processo di Generazione e Validazione
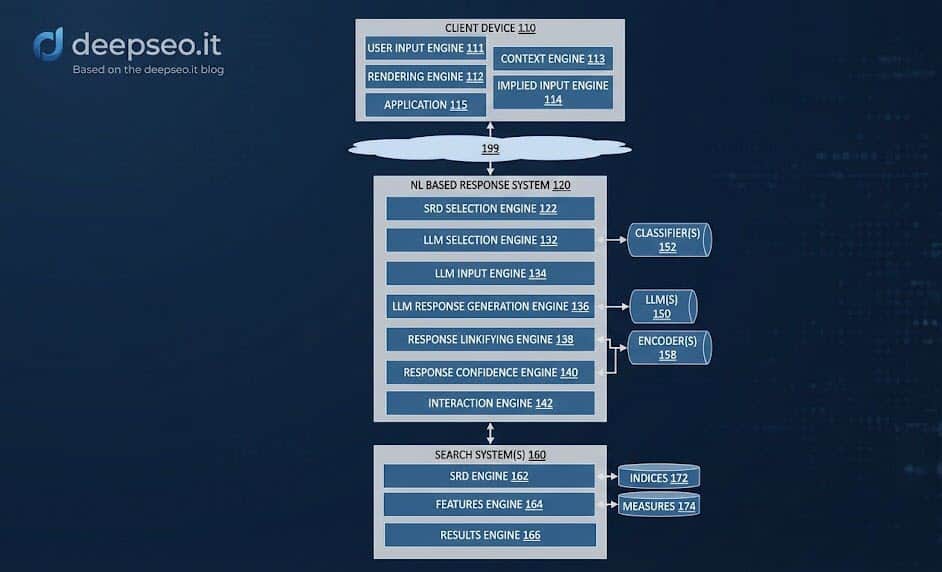
Il brevetto descrive un flusso critico:
-
Ricezione della Query: L’utente fa una domanda.
-
Identificazione dei Documenti: Il sistema recupera un set di risultati organici.
-
Generazione della Risposta: L’LLM genera una sintesi.
-
Confidence Check: Qui sta il trucco. Il brevetto cita esplicitamente un calcolo di un “Confidence Score”.
Se la confidenza del modello su una specifica affermazione (es. “Il Brand X è il migliore”) scende sotto una soglia $\theta$, il modello può scartare quella frase o sostituirla con un’altra fonte. Poiché la confidence varia leggermente ad ogni inferenza (a causa della temperatura vista sopra), la lista finale cambia.
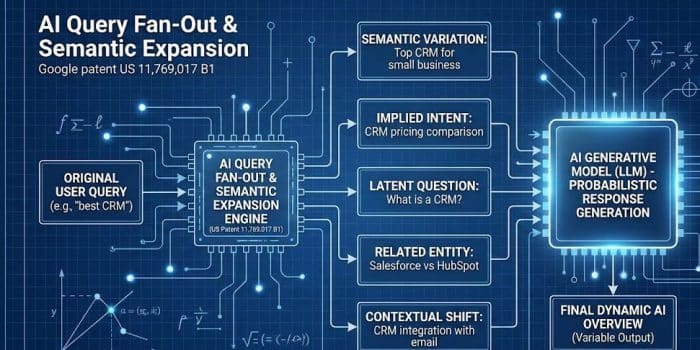
Query Fan-Out e Semantic Expansion
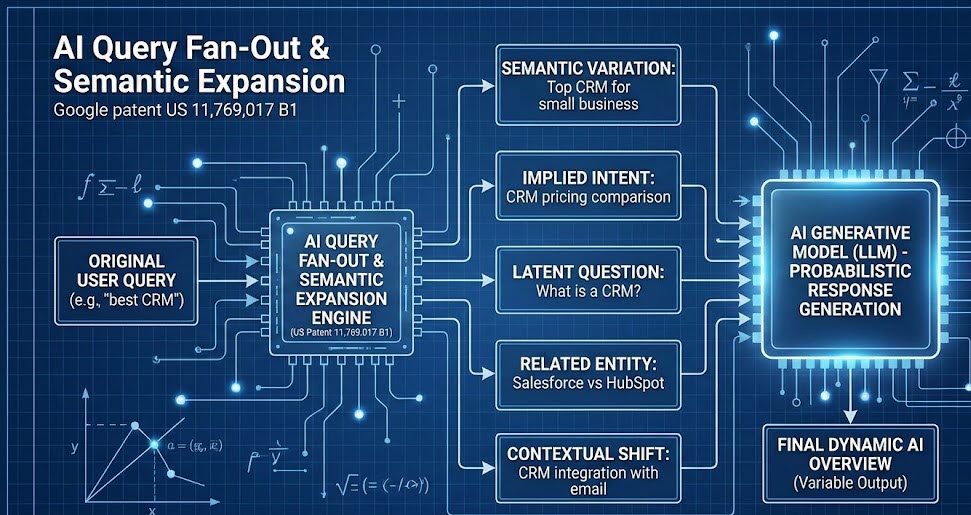
Un altro concetto chiave nel brevetto è l’espansione della richiesta. L’AI non risponde solo alla query esatta dell’utente. Esegue un Fan-Out (ventaglio) di query correlate per coprire l’argomento.Se il vostro contenuto è ottimizzato solo per la keyword esatta (vecchia SEO), rischiate di essere esclusi quando il modello decide di esplorare una variante semantica laterale durante la generazione.
La Mia Opinione personale: Benvenuti nella SEO Probabilistica
Cosa ci portiamo a casa da questa analisi tecnica? Che la SEO non è morta, ma è diventata molto più complessa. È passata dall’essere una disciplina deterministica (Input -> Output garantito) a una disciplina probabilistica.
Non possiamo più “garantire” la presenza in una risposta AI. Possiamo solo massimizzare la probabilità che la nostra entità venga campionata.
La Nuova Formula del Successo
Per aumentare $P(x_i)$ nella formula Softmax, dobbiamo lavorare su due fronti:
-
Aumentare il Logit ($z_i$):
Significa aumentare la “Salience” della nostra entità nel Knowledge Graph. Non bastano i backlink. Servono co-occorrenze, citazioni coerenti e una struttura semantica inattaccabile. Più il segnale è forte, più alta è la probabilità di essere “pescati” anche con Temperature elevate (non parliamo di caldo 🙂 ).
Cosa significa “Aumentare la salienza dell’entità nel Knowledge Graph”?
In termini tecnici (Semantic SEO), la Salienza (Salience) è una metrica precisa che Google usa nel suo motore di NLP (Natural Language Processing).
Immagina un testo che parla di “Automobili”.
-
Se la parola “Ferrari” appare una volta in una nota a piè di pagina, ha una salienza bassa (è marginale).
-
Se il testo parla della storia di Enzo Ferrari, del motore e delle vittorie, l’entità “Ferrari” ha una salienza alta (è il protagonista).
“Aumentare la salienza nel Knowledge Graph” significa quindi:
-
Non essere solo una “parola chiave”: Google non deve vederti come una stringa di testo (“vendita scarpe”), ma come un’Entità riconosciuta (Brand X, che è un negozio, situato a Milano, specializzato in scarpe).
-
Diventare il “Centro” dell’argomento: Fare in modo che quando Google analizza il tema (es. “Software CRM”), la tua azienda sia matematicamente associata a quel tema con un legame forte.
-
Uscire dall’ambiguità: Se ti chiami “Pippo”, Google deve capire inequivocabilmente che sei “Pippo l’agenzia SEO” e non “Pippo il personaggio Disney”.
-
-
Ridurre la Varianza Semantica:
Dobbiamo coprire l’argomento in modo così completo (Topical Authority reale) che qualsiasi “variazione” o Fan-Out generato dall’AI trovi comunque riscontro nei nostri contenuti.
Nel 2026, il SEO Specialist deve ragionare meno come un bibliotecario e più come un ingegnere statistico.Smettete di ossessionarvi sul perché oggi non siete apparsi nella risposta di ChatGPT.Iniziate a misurare la vostra Share of Model: su 1000 generazioni, quante volte appare il vostro brand? Questa è l’unica metrica che conta nell’era stocastica…secondo me ovviamente!
