Recentemente due articoli hanno suscitato grande “scalpore” in ambito SEO: Quello di Sparktoro e quello di ipullrank.com
Facciamo un riassunto e cerchiamo di capirne di più!
Fonti Rilevate: Google Leak
Recentemente, una fuga di informazioni ha rivelato dettagli cruciali sull’algoritmo di Google. Cerchiamo di esplorare in dettaglio le informazioni trapelate, le implicazioni per la SEO e offre un’analisi approfondita basata anche su ulteriori fonti autorevoli. Prossimamente avremo, spero, una video call con Rand e la inseriremo come approfondimento del corso.
Il leak dell’API del Content Warehouse di Google ha rivelato come i sistemi interni del motore di ricerca gestiscono il ranking dei contenuti. La documentazione, pubblicata accidentalmente, offre uno sguardo unico su come Google calcola e utilizza diversi segnali per generare le SERP. È importante considerare che non abbiamo accesso ai pesi specifici dei segnali di ranking e come questi vengano utilizzati nel processo complessivo. Le informazioni disponibili, sebbene incomplete, offrono comunque una significativa panoramica sui meccanismi di Google.
Caratteristiche di Ranking
Il leak rivela oltre 14.000 attributi di ranking distribuiti in 2.596 moduli, coprendo componenti come YouTube, Assistant e l’infrastruttura di crawling del web. Google utilizza un repository monolitico per gestire il codice e i dati dei suoi sistemi.

Dichiarazioni Fuorvianti di Google
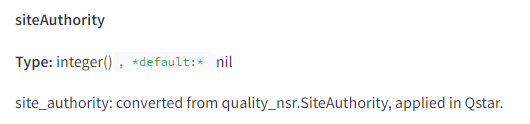
Google ha spesso negato l’uso di metriche come l’autorità del dominio. Tuttavia, la documentazione indica l’esistenza di una metrica chiamata “siteAuthority“, suggerendo che Google calcola e utilizza misure di autorità del sito.
Architettura dei Sistemi di Ranking di Google
Google non utilizza un singolo algoritmo, ma una serie di microservizi che preprocessano diverse funzionalità per comporre le SERP. Il sistema funziona su Spanner, un’architettura che consente la scalabilità infinita dello storage e del calcolo.
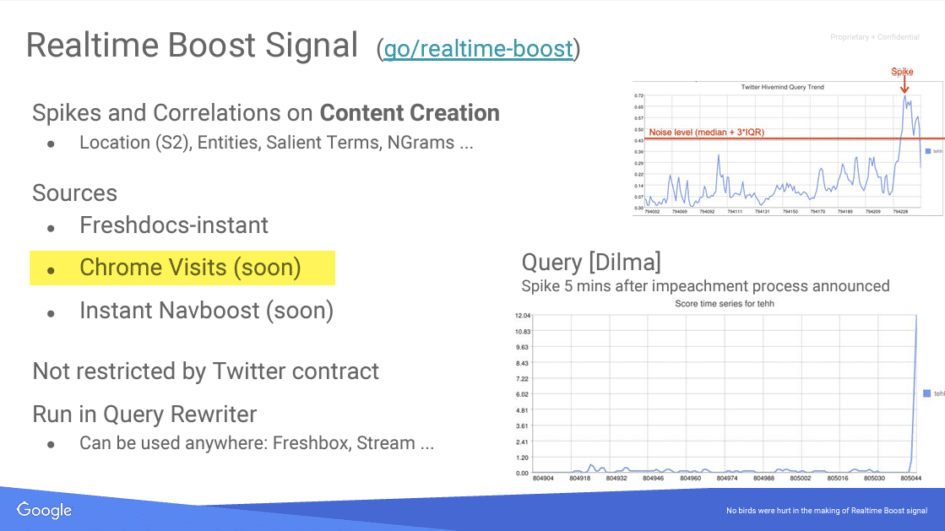
Twiddler e Sistemi di Boost
I “Twiddler” sono funzioni di ri-ranking eseguite dopo l’algoritmo principale di ricerca (Ascorer). Sistemi come NavBoost, QualityBoost e RealTimeBoost modificano i risultati della ricerca in base a vari segnali di comportamento degli utenti.
Rivelazioni Chiave
- Utilizzo di Clic per il Ranking: Contrariamente a quanto dichiarato, Google utilizza clic e comportamenti post-clic nei suoi algoritmi di ranking.
- Esistenza di un Sandbox: Google utilizza una funzione chiamata hostAge per “sandboxare” il contenuto nuovo e potenzialmente spam.
- Dati da Chrome: Google utilizza dati provenienti da Chrome per valutare la qualità delle pagine.
Il livello di indicizzazione influisce sul valore del collegamento
Una metrica chiamata sourceType mostra una relazione libera tra il luogo in cui è indicizzata una pagina e il suo valore. I contenuti meno importanti vengono archiviati su unità a stato solido, mentre i contenuti aggiornati in modo irregolare vengono archiviati su dischi rigidi standard.
In effetti, ciò significa che quanto più alto è il livello, tanto più prezioso è il collegamento. Anche le pagine considerate “fresche” sono considerate di alta qualità. Basti dire che vuoi che i tuoi collegamenti provengano da pagine nuove o altrimenti presenti nel livello più alto. Ciò spiega in parte perché ottenere classifiche da pagine con un ranking elevato e da pagine di notizie produce prestazioni di posizionamento migliori 🙂
Lunghezza dei contenuti?
Google analizza la struttura dei documenti contando i “token”, ovvero le unità di testo come parole o simboli, e confrontando il numero totale di parole con il numero di token unici. La documentazione rivela che c’è un limite massimo al numero di token considerati per ogni documento all’interno del sistema Mustang. Questo sottolinea l’importanza per gli autori di includere i punti chiave all’inizio dei loro testi.
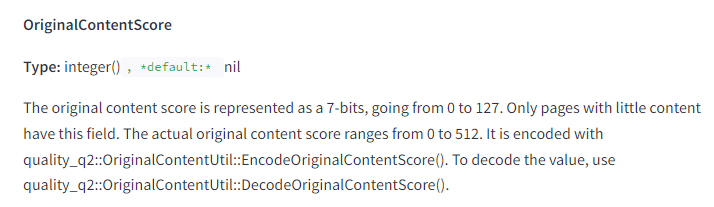
Per quanto riguarda i contenuti brevi, essi ricevono un punteggio basato sulla loro originalità, indicato come “OriginalContentScore“. Questo suggerisce che la brevità di un contenuto non è necessariamente un indicatore della sua qualità, ma piuttosto l’unicità e l’originalità sono valutate.
Inoltre, esiste anche un punteggio relativo all’uso eccessivo di parole chiave, indicando che un testo non deve essere sovraccaricato di termini chiave nel tentativo di manipolare i risultati di ricerca.
Infine, i titoli delle pagine sono ancora valutati in base a quanto bene corrispondono alle query di ricerca degli utenti. Un “titlematchScore” esiste per quantificare quanto bene un titolo di pagina si allinea con le ricerche effettuate, riflettendo l’importanza che Google continua a dare alla pertinenza del titolo rispetto alla query dell’utente.
Le date nei contenuti
L’importanza delle date nei contenuti web è particolarmente evidenziata dall’attenzione che Google riserva ai risultati aggiornati. La documentazione esamina vari metodi attraverso i quali Google associa le date alle pagine:
- bylineDate: È la data chiaramente specificata sulla pagina.
- syntacticDate: È la data che può essere rilevata dall’URL o presente nel titolo della pagina.
- semanticDate: Corrisponde alla data dedotta dal contesto del contenuto stesso.
Per massimizzare l’efficacia della datazione sui contenuti, è cruciale mantenere coerenza tra le date esplicitate nei diversi formati utilizzati online: nei dati strutturati, nei titoli delle pagine e nelle mappe dei siti XML. È importante evitare discrepanze nelle date tra l’URL e altri elementi della pagina, poiché questo potrebbe compromettere la visibilità e l’efficacia del contenuto agli occhi di Google.
Ci sarebbe molto altro da dire ma aspetterei la lettura approfondita degli articoli.
Quindi?
- Utilizzo di un repository monolitico per la gestione di codici e dati, facilitando analisi incrociate tra varie piattaforme.
- Contrariamente alle dichiarazioni ufficiali, Google utilizza dati basati sui clic degli utenti per influenzare i risultati di ricerca.
- Presenza di una metrica chiamata “siteAuthority” che valuta l’importanza di un sito, simile al concetto di Domain Authority negato da Google.
- Importanza degli aggiornamenti recenti nei risultati, con Google che si concentra particolarmente su contenuti freschi e aggiornati.
- Navboost: Questo sistema sfrutta le metriche basate sui clic degli utenti per modificare il ranking delle pagine nei risultati di ricerca, differenziando tra tipi di clic.
- Sandbox per Spam: Google utilizza un attributo chiamato “hostAge” per filtrare lo spam recente, isolandolo in una sorta di sandbox.
- Importanza degli Autori: Google tiene traccia degli autori dei documenti, esaminando anche se un’entità sulla pagina è l’effettivo autore.
- Varie Forme di “Deprezzamento”: Link non pertinenti, comportamenti degli utenti su SERP, e altre metriche influenzano la valutazione delle pagine.
- Valore dei Link: I link da siti aggiornati frequentemente e recenti sono particolarmente preziosi.
Intanto la SEO è cambiata? A detta di questi documenti molto è rimasto uguale, molto cambierà… ma l’importanza è l’aggiornamento costante!
Vi aggiorneremo sui risultati di queste rivelazioni e faremo lezioni ad hoc nel nostro corso!!!
Fonti: Sparktoro e ipullrank.com
